Data Fetching

After formulating an idea (we’re going to try and predict technical scores of international figure skating elements) the next step is to fetch the data.
This can be anything from a moderate to an enormous faff, but in this case it’s relatively straightforward as the information we need is available in a predictable and friendly format from skatingscores.
This post shows how to scrape this information in a considerate way (i.e. without putting too much pressure on the data provider’s server) and save it in a format that will be easy to do some analysis on later.
A couple of potentially attention-saving disclaimers:
- If you are looking for figure skating data, using the skatingscores database query functionality may well be easier than adapting the method I used here.
- If you are mostly interested in analysis and not so much in scraping and data wrangling, you may want to skip to the next post.
If none of these apply to you, read on!
Preamble
The first step is to have a look at the kind of page we want to scrape and decide what to try and fetch from it.
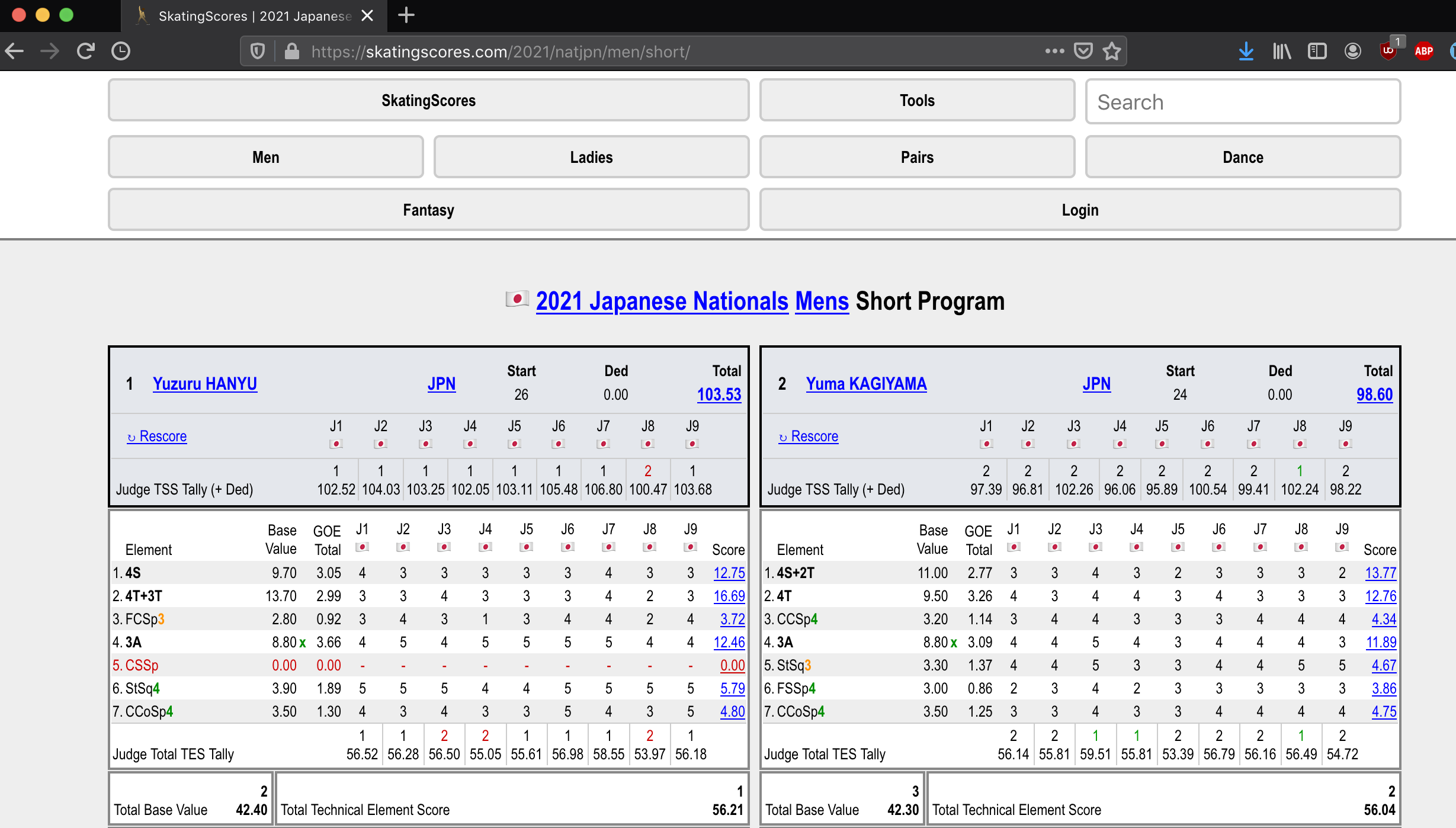
We are interested in the stripy tables of element scores, the blue skater names, the big event title and the nicely formatted url.
Now we’re ready to start writing a python script to fetch the data.
Imports
The most important import this script uses is the html parsing library BeautifulSoup - I’d highly recommend reading the documentation at that link if you’re interested in scraping. We’ll also use pandas to make the data tabular, requests for talking to the internet and some built in python libararies for string manipulation (re) and temporarily pausing (time).
from bs4 import BeautifulSoup
import re
import requests
import pandas as pd
import time
Urls
The skatingscores urls we need have the format
https://skatingscores.com/<SEASON>/<EVENT_NAME>/<GENDER>/<PROGRAM>, so the
urls we need to query can be specified with only the following hardcoded
information:
BASE_URL = "https://skatingscores.com"
EVENTS = [
"1920/gpcan",
"1920/gpchn",
"1920/gpjpn",
"1920/gpfra",
"1920/gpusa",
"1920/gpf",
"1920/gpf",
"1920/4cc",
"2021/natjpn",
"2021/natusa"
]
GENDERS = ["men", "ladies"]
PROGRAMS = ["short", "long"]
These can be turned into a list of urls with a simple function:
def get_urls(base_url, events, genders, programs):
return [
f"{base_url}/{event}/{gender}/{program}"
for event in events
for gender in genders
for program in programs
]
Fetching html considerately
The next step is to fetch an html string for each url from the internet and turn them into BeautifulSoup objects. The following functions take care of this:
def fetch_html(url):
time.sleep(0.2) # to avoid overloading the skatingscores server
try:
r = requests.get(url)
r.raise_for_status()
return r.content
except requests.exceptions.HTTPError as err:
raise SystemExit(err)
def fetch_soups(urls):
return [BeautifulSoup(fetch_html(url), 'html.parser') for url in urls]
Note that the fetch_html function includes a brief pause to avoid overloading
the target server, and that these functions use the verb “fetch” to indicate
that they interact with the outside world.
From Beautiful soup to native python
The next step is to extract information we want - i.e. the event name for each program and the skater name and score table for each skate - from our list of BeautifulSoup objects and put them in native python objects.
The easiest thing to get is the event name. The function below finds the text
of a parsed page’s first h1 element (soup.find("h1").text), filters out
non-alphanumeric characters (re.sub(...)) and removes any leading whitespace
(.lstrip()).
def get_event_name(soup):
return re.sub(r'[^A-Za-z0-9 ]+', '', soup.find("h1").text).lstrip()
The skate-specific information, i.e. the name and country of each skater and
the table recording their technical scores, lives in html divs with the class
skat-wrap. We can get a list of BeautifulSoup obejects representing all the
skat-wrap elements for a page with another function:
def get_skates(soup):
return soup.find_all("div", {"class": "skat-wrap"})
The skater’s name and country are always the text of the first two links in the
header row of a skate table. This function extracts that information from a
BeautifulSoup object representing a skat-wrap div:
def get_name_and_country(skate_soup):
headlinks = (
skate_soup
.find("div", class_="ptab1-wrap")
.find("table")
.find("tr", class_="head")
.find_all("a")
)
name = " ".join([n.capitalize() for n in headlinks[0].text.split(" ")])
country = headlinks[1].text
return name, country
The table of scores for each skate lives in the table element of a div with
the class ptab2-wrap. We can get the required information by filtering out
the head and tally rows and then extracting the text of each td element
of each remaining row:
def get_score_table(skate_soup):
exclude = {"head", "tally"}
rows = list(filter(
lambda r: len(set(r.attrs["class"]) & exclude) == 0,
skate_soup
.find("div", class_="ptab2-wrap")
.find("table")
.find_all("tr")
))
return [[td.text for td in r.find_all("td")] for r in rows]
Putting everything together from this step, we can now turn a BeautifulSoup representing an event page into the event name and a list of sub-soups representing skates, and we can turn each skate soup into a name/country tuple and a list with technical score information.
Now we need to put these bits together to get a single, nicely formatted table.
From native python to a table
First we need to decide what we want our table to look like - what should its rows represent?
I think a good choice is for the rows to represent assignments of technical scores by individual judges - i.e. the numbers between -5 and +5 in the screenshot above. This is nice because these are the most fine-grained bits of information, and also fits the tidy data philosophy that table rows should usually represent individual measurements.
In other words we want to end up with something like this:
event name judge score
2021 Japanese Nationals Mens Short Program Yuzuru Hanyu 1 4
2021 Japanese Nationals Mens Short Program Yuzuru Hanyu 1 3
...
The next function does most of the work to turn the native python objects that
the previous steps creted into a pandas DataFrame with the tabular form we are
looking for. The main trick is the call to the
melt
method, which reshapes the table from wider form in which it appears on
skatingscores to the longer form we want.
def get_df_from_skate(event, name, country, score_table):
n_judge = len(score_table[0]) - 7
judge_cols = [str(i+1) for i in range(n_judge)]
pre_cols = ["order", "element", "notes", "base_value", "late", "goe_total"]
post_cols = ["aggregate_score"]
cols = pre_cols + judge_cols + post_cols
return (
pd.DataFrame(score_table, columns=cols)
.assign(late=lambda df: df["late"].map({"x": True, "": False}))
.melt(id_vars=pre_cols+post_cols, var_name="judge", value_name="score")
.assign(event=event, name=name, country=country)
.apply(pd.to_numeric, errors="ignore", downcast="integer")
)
Putting everything together
The last step in the process is to make a couple of functions to glue the different parts together. First we need a function that takes in a page soup, makes a table for each skate, and stacks all of these tables together:
def get_df_from_soup(soup):
event = get_event_name(soup)
skates = get_skates(soup)
out = pd.DataFrame()
for skate in skates:
name, country = get_name_and_country(skate)
score_table = get_score_table(skate)
score_df = get_df_from_skate(event, name, country, score_table)
out = pd.concat([out, score_df], ignore_index=True)
return out
Finally, we make another function that takes a list of page soups, gets tables from them and stacks the results:
def get_df_from_soups(soups):
return pd.concat(
[get_df_from_soup(soup) for soup in soups], ignore_index=True
)
Now we really have everything we need, so we can write our script’s main function:
def main():
urls = get_urls(BASE_URL, EVENTS, GENDERS, PROGRAMS)
print("Fetching data...")
soups = fetch_soups(urls)
print("Processing data...")
scores = get_df_from_soups(soups)
print(f"Writing data to {OUTPUT_FILE}")
scores.to_csv(OUTPUT_FILE)
if __name__ == "__main__":
main()
Here’s what the final script looks like.
Now we can run the script with python fetch_scores.py and see something like
this:
tedgro@nnfcb-l0601 ~/Code/figure_skating (master)
$ python fetch_scores.py
Fetching data...
Processing data...
Writing data to scores.csv
and then check that the output looks as expected
tedgro@nnfcb-l0601 ~/Code/figure_skating (master)
$ echo -e "import pandas as pd\nprint(pd.read_csv('scores.csv').iloc[0])" | python
Unnamed: 0 0
order 1
element 4S
notes NaN
base_value 9.7
late False
goe_total 4.43
aggregate_score 14.13
judge 1
score 5
event 2019 GP Skate Canada Mens Short Program
name Yuzuru Hanyu
country JPN
Name: 0, dtype: object
Conclusion
So, that was how I fetched some skating data from skatingscores.
The next post in this series will get started with analysing this data. Until then goodbye and happy scraping!